微服务架构中的熔断器设计与实现(Golang版)
贺鹏 目前就职某互联网金融公司负责架构及开发管理工作,在分布式领域和风控领域深入研究。
I.内容提要
在微服务架构中,经常会碰到服务超时或通讯失败的问题,由于服务间层层依赖,很可能由于某个服务出现问题,不合理的重试和超时设置,导致问题层层传递引发雪崩现象,而限流和熔断是解决这个问题重要的方式。之前发过一篇文章讲了限流的几种实现方案,具体参阅:
分布式高并发服务限流实现方案
今天我们探讨熔断的话题,本章内容提要:
微服务高可用容错机制
- 熔断器设计原理及 Golang 实现
- 服务网格和代理网关熔断机制
II.微服务容错机制
微服务架构中,服务的依赖和调用关系变得错综复杂,带来灵活性的同时,对服务稳定性也带来了新的隐患。如下图所示,当 “服务C” 出现问题时,可能是宕机,上线出 bug,流量过大或缓存穿透数据库压垮服务,这时“服务 C”响应就会出问题,而“服务 B”由于拿不到响应结果又会不断重试进一步压垮“服务 C”,同时“服务 B”同步调用也会有大量等待线程,出现资源耗尽,导致“服务 B”变得不可用,进而影响到“服务 A”,形成雪崩效应。

为了解决雪崩效应,要建立有效的 服务容错机制,一方面服务要做到冗余,建立 集群,依托 负载均衡机制和 重试机制,保障服务可用性。
当服务出错时,可以设置不同的策略:
Failover 失败转移
- Failback 失败通知
- Failsafe 失败安全
- Failfast 快速失败
除了集群容错外,对服务的熔断和限流也是必要的措施,虽然两者经常相伴出现,却是不同的保护机制。限流是防止上游服务调用量过大导致当前服务被压垮,熔断是预防下游服务出现故障时阻断对下游的调用。
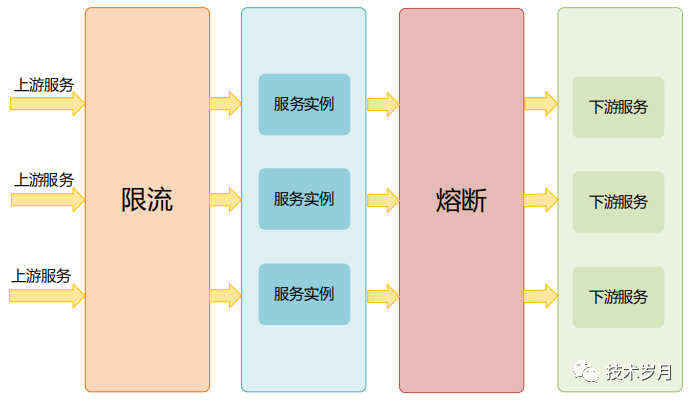
III.熔断器设计实现
设计思想
熔断器的概念源自电路系统的熔断器,当电路过大,会自动切断进行保护,后来被应用到金融股票中,今年美股股市就发生了多起熔断。微服务中的熔断设计理念如出一辙。

(图片来自网络)
熔断器设计模式是基于 AOP 对所有的请求调用进行拦截,在请求调用前做状态判断是否熔断,请求调用后做计数统计,并根据策略做熔断状态转移。
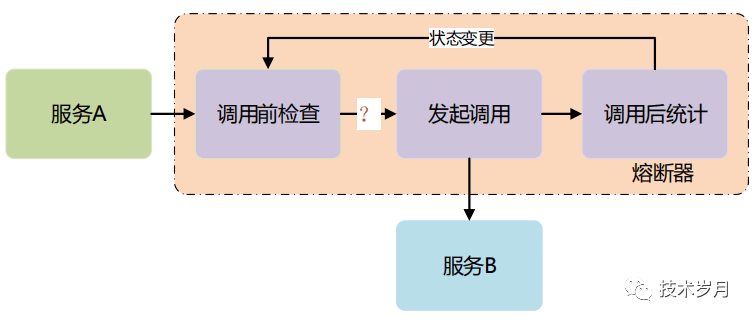
熔断器涉及 三种状态和 四种状态转移,理解了这张图基本理解了熔断的设计精髓。

构造熔断器
首先定了熔断器结构体如下:
typeServiceBreaker struct{
mu sync.RWMutex
name string
state State
windowInterval time.Duration
metrics Metrics
tripStrategyFunc TripStrategyFunc
halfMaxCalls uint64
stateOpenTime time.Time
sleepTimeout time.Duration
stateChangeHook func(name string, fromState State, toState State)
}
结构体字段较多,先了解基本参数,其他参数后续使用中展开。
- mu 读写锁,在并发情况下保障熔断器状态正常
- name 熔断器名字,方便查询和日志标识
- state 熔断器状态,三种状态,这里定义为 State 结构
typeState int
const(
StateClosed State = iota
StateOpen
StateHalfOpen
)
func(s State)Stringstring{
switchs {
caseStateClosed:
return"closed"
caseStateHalfOpen:
return"half-open"
caseStateOpen:
return"open"
default:
returnfmt.Sprintf( "unknown state: %d", s)
}
}
初始化构造熔断器实例,传入配置参数列表。
//new breaker
funcNewServiceBreaker(op Option)(*ServiceBreaker, error){
ifop.WindowInterval <= 0|| op.HalfMaxCalls <= 0|| op.SleepTimeout <= 0{
returnnil, errors.New( "incomplete options")
}
breaker := new(ServiceBreaker)
breaker.name = op.Name
breaker.windowInterval = op.WindowInterval
breaker.halfMaxCalls = op.HalfMaxCalls
breaker.sleepTimeout = op.SleepTimeout
breaker.stateChangeHook = op.StateChangeHook
breaker.tripStrategyFunc = ChooseTrip(&op.TripStrategy)
breaker.nextWindow(time.Now)
returnbreaker, nil
}
执行调用流程
通过引入熔断器 包裹执行流程,具体包括三个阶段:
- 熔断器在执行前先调用 beforeCall ,判定是否可以执行
- 执行远程服务调用并返回执行结果
- 执行完成后调用 afterCall 进行指标统计和状态更新
func(breaker *ServiceBreaker)Call(exec func( interface{}, error) ) ( interface{}, error) {
//before call
err := breaker.beforeCall
iferr != nil{
returnnil, err
}
//if panic occur
deferfunc{
err := recover
iferr != nil{
breaker.afterCall( false)
panic(err)
}
}
//call
breaker.metrics.OnCall
result, err := exec
//after call
breaker.afterCall(err == nil)
returnresult, err
}
调用前检查
接着重点来了,在 beforeCall 具体如何进行检查和拦截的呢?先看代码:
func(breaker *ServiceBreaker)beforeCallerror{
breaker.mu.Lock
deferbreaker.mu.Unlock
now := time.Now
switchbreaker.state {
caseStateOpen:
//after sleep timeout, can retry
ifbreaker.stateOpenTime.Add(breaker.sleepTimeout).Before(now) {
log.Printf( "%s 熔断过冷却期,尝试半开n", breaker.name)
breaker.changeState(StateHalfOpen, now)
returnnil
}
log.Printf( "%s 熔断打开,请求被阻止n", breaker.name)
returnErrStateOpen
caseStateHalfOpen:
ifbreaker.metrics.CountAll >= breaker.halfMaxCalls {
log.Printf( "%s 熔断半开,请求过多被阻止n", breaker.name)
returnErrTooManyCalls
}
default: //Closed
if!breaker.metrics.WindowTimeStart.IsZero && breaker.metrics.WindowTimeStart.Before(now) {
breaker.nextWindow(now)
returnnil
}
}
returnnil
}
判断熔断器的状态,对三种状态分别分析:
- 关闭状态,默认肯定是关闭的,这个时候不做任何拦截,这里 return nil ,但是对统计窗口做检查 变更 ,一会具体分析统计窗口的逻辑。
- 半开状态,也就是说会放一些请求通过进行试探,放多少量呢?这里涉及到一个参数 halfMaxCalls ,在熔断器初始化时设置,超了返回 ErrTooManyCalls 错误。
- 开启状态,这时候肯定不能访问了,所以返回了 ErrStateOpen 错误,但是这里会涉及到一个状态转移,如果过了冷却时间,会进入半开状态尝试调用。
这里定义了两种错误类型。
var(
ErrStateOpen = errors.New( "service breaker is open")
ErrTooManyCalls = errors.New( "service breaker is halfopen, too many calls")
)
执行请求调用
只有beforeCall 返回为 nil 的时候,可以执行调用,否则就直接返回错误。
执行调用前先做 breaker.metrics.OnCall 计数统计,执行请求并返回结果和错误,根据返回情况来统计并处理 breaker.afterCall(err == nil) 。
调用后处理逻辑
再来看下 afterCall 这个方法,这个方法接收请求调用的结果,并分别对执行成功和执行失败进行处理。
func(breaker *ServiceBreaker)afterCall(success bool) {
breaker.mu.Lock
deferbreaker.mu.Unlock
ifsuccess {
breaker.onSuccess(time.Now)
} else{
breaker.onFail(time.Now)
}
}
统计窗口
这里先插入分析下统计窗口,它也算熔断器设计中的核心模块。
typeMetrics struct{
WindowBatch uint64
WindowTimeStart time.Time
CountAll uint64
CountSuccess uint64
CountFail uint64
ConsecutiveSuccess uint64
ConsecutiveFail uint64
}
参数看着比较多,但理解起来比较简单,分别记录窗口的批次,窗口开始的时间,窗口期内所有请求数,所有成功数,所有失败数,连续成功数,连续失败数,通过下图一看便知。
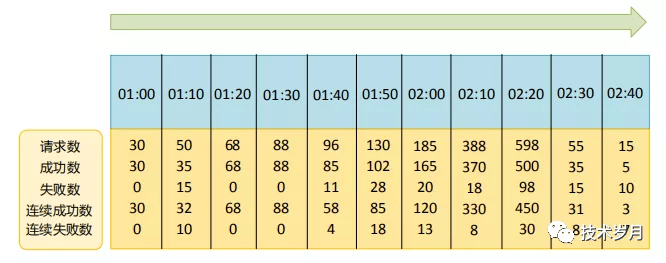
封装一些方法进行计数统计,这里注意成功或失败的时候对连续成功和连续失败要清零。
func(m *Metrics)NewBatch{
m.WindowBatch++
}
func(m *Metrics)OnCall{
m.CountAll++
}
func(m *Metrics)OnSuccess{
m.CountSuccess++
m.ConsecutiveSuccess++
m.ConsecutiveFail = 0
}
func(m *Metrics)OnFail{
m.CountFail++
m.ConsecutiveFail++
m.ConsecutiveSuccess = 0
}
func(m *Metrics)OnReset{
m.CountAll = 0
m.CountSuccess = 0
m.CountFail = 0
m.ConsecutiveSuccess = 0
m.ConsecutiveFail = 0
}
看下统计窗口变动操作,在初始化熔断器和熔断器状态变更的时候都会新开统计窗口。
func(breaker *ServiceBreaker)nextWindow(now time.Time){
breaker.metrics.NewBatch
breaker.metrics.OnReset //clear count num
varzero time.Time
switchbreaker.state {
caseStateClosed:
ifbreaker.windowInterval == 0{
breaker.metrics.WindowTimeStart = zero
} else{
breaker.metrics.WindowTimeStart = now.Add(breaker.windowInterval)
}
caseStateOpen:
breaker.metrics.WindowTimeStart = now.Add(breaker.sleepTimeout)
default: //halfopen
breaker.metrics.WindowTimeStart = zero //halfopen no window
}
}
具体逻辑为,开启新的窗口批次,所有计数清零。
根据当前熔断器状态:
熔断器关闭,窗口时间滚动一个时间窗口期windowInterval,时间窗口期也是 breaker 初始化时设置,计数统计发生在同一窗口期
- 熔断器打开,过了冷却期状态转移为半开,会进入新的计数窗口期,窗口期开始时间增加 冷却期休眠时间 sleepTimeout
半开状态,不做窗口期处理
执行成功逻辑
回到afterCall ,如果调用成功,会对计数器进行成功统计。
func(breaker *ServiceBreaker)onSuccess(now time.Time){
breaker.metrics.OnSuccess
ifbreaker.state == StateHalfOpen
&& breaker.metrics.ConsecutiveSuccess >= breaker.halfMaxCalls { breaker.changeState(StateClosed, now)}
}
这里还是要考虑熔断器的状态,熔断器开启肯定无法走到这里,熔断器关闭且调用成功了,正常计数即可。而熔断器如果处于半开状态,会涉及到可能发生状态转移,由半开到关闭。什么情况从半开回到关闭呢?
breaker.metrics.ConsecutiveSuccess >= breaker.halfMaxCalls
这里使用的策略是连续成功数 >= breaker.halfMaxCalls,这个要求比较严格,也就是说要服务在半开状态下,每次尝试的调用都要成功。当然这里也可以根据你的生产场景来定制不同的恢复策略。
状态转移
那么看下状态转移的逻辑是什么?
func(breaker *ServiceBreaker)changeState(state State, now time.Time){
ifbreaker.state == state {
return
}
prevState := breaker.state
breaker.state = state
//goto next window,reset metrics
breaker.nextWindow(time.Now)
//record open time
ifstate == StateOpen {
breaker.stateOpenTime = now
}
//callback hook
ifbreaker.stateChangeHook != nil{
breaker.stateChangeHook(breaker.name, prevState, state)
}
}
状态变更,开启新的统计窗口(之前的计数清零),熔断器打开状态要记录下当前时间保存到 breaker.stateOpenTime 中。这里还有一个状态变更钩子,如果在熔断器配置中配置了,钩子函数会进行调用。
breaker.stateChangeHook(breaker.name, prevState, state)
执行失败逻辑
如果 afterCall 发现调用失败了,涉及到哪些逻辑呢?
func(breaker *ServiceBreaker)onFail(now time.Time){
breaker.metrics.OnFail
switchbreaker.state {
caseStateClosed:
ifbreaker.tripStrategyFunc(breaker.metrics) {
breaker.changeState(StateOpen, now)
}
caseStateHalfOpen:
breaker.changeState(StateOpen, now)
}
}
先做失败统计,然后分状态进行处理并判断是否发生状态转移。
状态半开,如果失败了直接转为关闭,严格模式。
- 状态关闭,会根据策略判断是否要开启熔断。
失败一次不可怕,如果失败过多就要熔断了,那么多少是多呢?这里主要看熔断策略 tripStrategyFunc设置。
熔断策略
首先它也是在熔断器初始化时设置的,类型为结构体 TripStrategyFunc
tripStrategyFunc TripStrategyFunc
那么有哪些可参考的策略呢?
根据错误计数,如果一个时间窗口期内失败数 >= n 次,开启熔断。
- 根据连续错误计数,一个时间窗口期内连续失败 >=n 次,开启熔断。
根据错误比例,一个时间窗口期内错误占比 >= n (0 ~ 1),开启熔断,但这里为了防止极端情况,如窗口期第一次请求就失败了,这时错误占比是 1,所以会有一个最小调用量限制。
看下具体代码实现:
//when error occur, determine whether the breaker should be opened.
typeTripStrategyFunc func(Metrics)bool
//according to consecutive fail
funcConsecutiveFailTripFunc(threshold uint64) TripStrategyFunc{
returnfunc(m Metrics)bool{
returnm.ConsecutiveFail >= threshold
}
}
//according to fail
funcFailTripFunc(threshold uint64) TripStrategyFunc{
returnfunc(m Metrics)bool{
returnm.CountFail >= threshold
}
}
//according to fail rate
funcFailRateTripFunc(rate float64, minCalls uint64) TripStrategyFunc{
returnfunc(m Metrics)bool{
varcurrRate float64
ifm.CountAll != 0{
currRate = float64(m.CountFail) / float64(m.CountAll)
}
returnm.CountAll >= minCalls && currRate >= rate
}
}
将这几种策略封装并通过配置化选择。
const(
ConsecutiveFailTrip = iota+ 1
FailTrip
FailRateTrip
)
//choose trip
funcChooseTrip(op *TripStrategyOption)TripStrategyFunc{
switchop.Strategy {
caseConsecutiveFailTrip:
returnConsecutiveFailTripFunc(op.ConsecutiveFailThreshold)
caseFailTrip:
returnFailTripFunc(op.FailThreshold)
caseFailRateTrip:
fallthrough
default:
returnFailRateTripFunc(op.FailRate, op.MinCall)
}
}
funcNewServiceBreaker(op Option)(*ServiceBreaker, error){
//...
breaker.tripStrategyFunc = ChooseTrip(&op.TripStrategy)
//...
}
熔断测试
最后再来回看下熔断器的参数配置:
- windowInterval 每个窗口的时间间隔
- metrics 统计窗口
- tripStrategyFunc 熔断策略
- halfMaxCalls 半开状态下尝试调用的次数
- sleepTimeout 熔断开启后的冷却休眠时间,过了休眠期尝试半开
- stateChangeHook 状态变更执行钩子函数
通过引入 option 来进行配置。
typeTripStrategyOption struct{
Strategy uint
ConsecutiveFailThreshold uint64
FailThreshold uint64
FailRate float64
MinCall uint64
}
typeOption struct{
Name string
WindowInterval time.Duration
HalfMaxCalls uint64
SleepTimeout time.Duration
StateChangeHook func(name string, fromState State, toState State)
TripStrategy TripStrategyOption
}
通过几个测试用例来看下熔断器效果。
先初始化一个熔断器,循环执行调用,先执行成功,中间执行失败累积到一定量开启熔断,然后再恢复正常。
funcinitBreaker* ServiceBreaker{
tripOp := TripStrategyOption{
Strategy: FailRateTrip,
FailRate: 0.6,
MinCall: 3,
}
option := Option{Name: "breaker1",
WindowInterval: 5* time.Second,
HalfMaxCalls: 3,
SleepTimeout: 6* time.Second,
TripStrategy: tripOp,
StateChangeHook: stateChangeHook,
}
breaker, _ := NewServiceBreaker(option)
returnbreaker
}
funcTestServiceBreaker(t *testing.T){
breaker := initBreaker
fori := 0; i < 30; i++ {
breaker.Call( func( interface{}, error) {
ifi <= 2|| i >= 8{
fmt.Println( "请求执行成功!")
returnnil, nil
} else{
fmt.Println( "请求执行出错!")
returnnil, errors.New( "error")
}
})
time.Sleep( 1* time.Second)
}
}
funcstateChangeHook(name string, fromState State, toState State) {
fmt.Printf( "熔断器%v 触发状态变更:%v --> %vn", name, fromState, toState)
}
也可以切换不同的熔断策略和阈值配置,查看效果。执行情况如下:
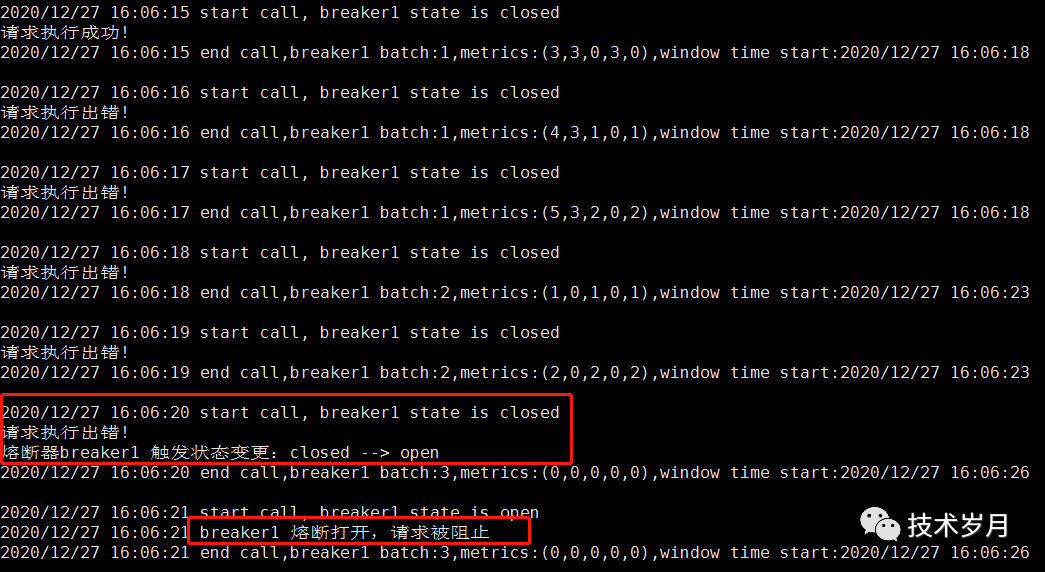
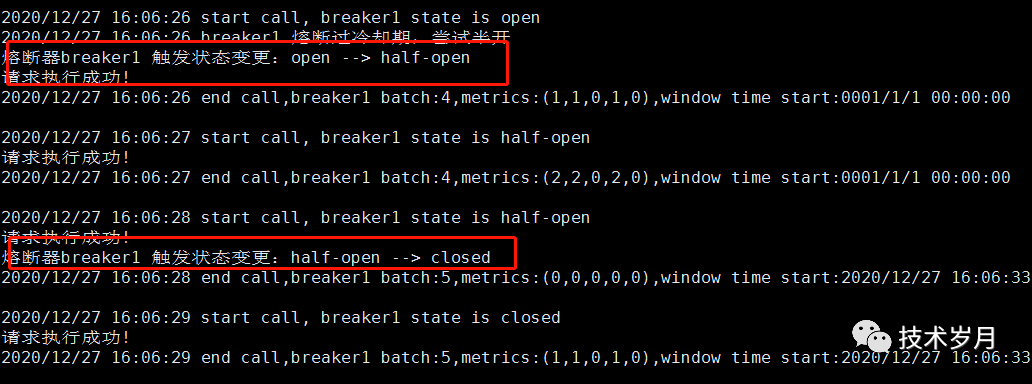
并发情况下,开启 5 个并发,每个并发内循环执行调用,查看熔断情况。
funcTestServiceBreakerInParallel(t *testing.T){
runtime.GOMAXPROCS(runtime.NumCPU)
breaker := initBreaker
varwg sync.WaitGroup
fori := 0; i < 5; i++ { //并发5
wg.Add( 1)
deferwg.Done
gofunc{
forj := 0; j < 30; j++ {
breaker.Call( func( interface{}, error) {
ifj <= 2|| j >= 8{
fmt.Println( "请求执行成功!")
returnnil, nil
} else{
fmt.Println( "请求执行出错!")
returnnil, errors.New( "error")
}
})
time.Sleep( 1* time.Second)
}
}
}
wg.Wait
}
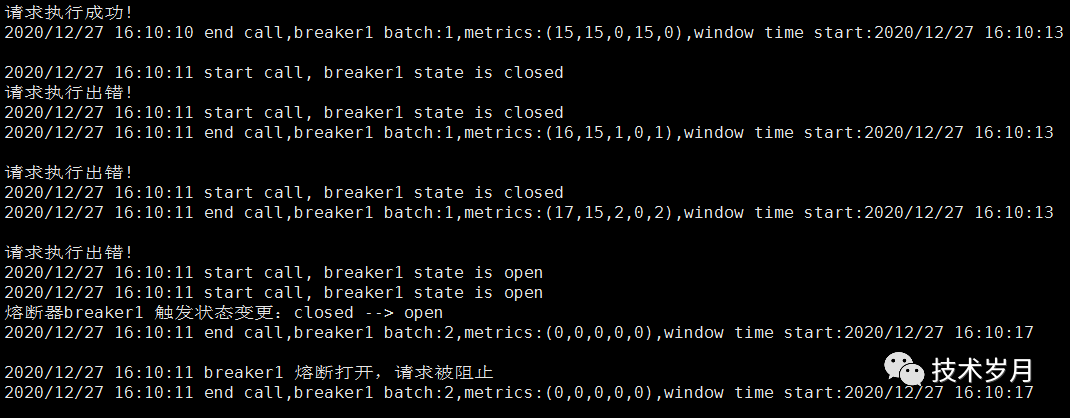
总结
最后做个总结,通过下图可以看到完整熔断器设计逻辑。

IV.设计模式思考
设计模式思想
上述设计思想源自 Microsoft 《Circuit Breaker Pattern》,代码参考 Sony开源实现,请求同步串行化,由于前置后置操作和锁的存在导致请求性能降低,存在并发问题。
在熔断领域中,还有大名鼎鼎的 Hystrix (有 Java 和 Golang 版本),是 Netflix 开源的限流熔断项目,它支持并发请求,异步上报统计结果提高了并发性。
以上使用方式均为组件方式,需要整合到微服务框架中,以包或 SDK 方式存在代码中,有代码侵入性,这种微服务调用方式主要为直连模块。
根据服务发现和服务调用的不同,主要有三种方式:
直连模式,服务A 直接访问 服务 B
- 集中代理模式,通过引入内网网关做代理, 调用时通过网关做转发和负载均衡
还有目前比较火的 服务网格模式 Service Mesh,也叫边车模式 SideCar
代理模式集中网关
集中网关代理模式,所有服务调用统一经过网关,再由网关转发到达,相应可以方便的在网关层做限流、熔断。这里提供一种基于异步统计的熔断方案。
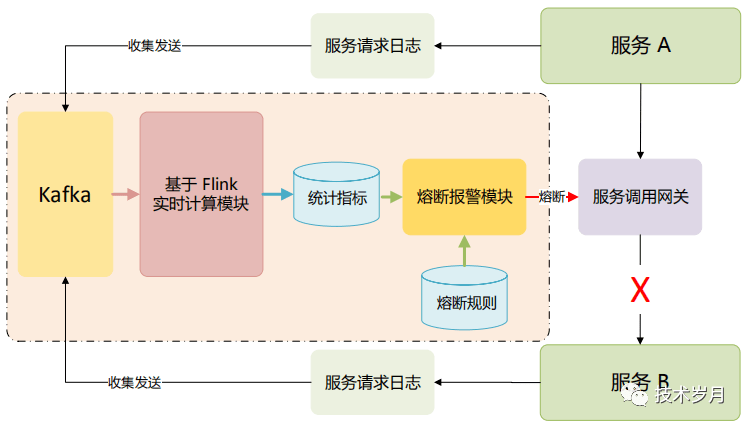
设计的主要思想,对服务请求日志做收集和指标计算,通过熔断报警模块下发熔断指令给服务网关,网关对请求进行拦截。这种方案指标采集统计完全异步化,优点在于对请求性能几乎无影响,但缺点在于依赖消息队列和实时计算模块对服务熔断判断存在一定延时,集中网关本身也有单点故障的风险。
服务网格模式
服务网格模式本质是将 SDK 代码独立 部署成单独进程,与服务机器共存,并作为服务请求和接收的代理,相比于直连方式增加了两个节点,如下图所示。
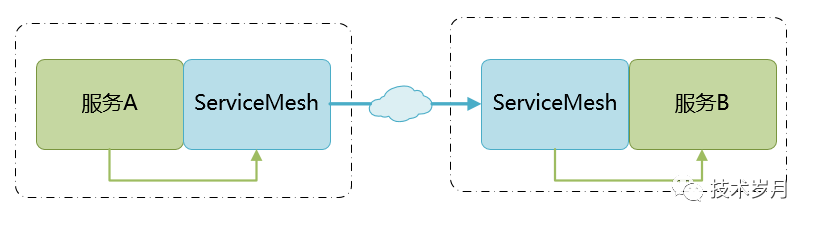
可以在 ServiceMesh 中做服务的调用重试、超时控制,以及熔断和限流机制。熔断开发思路和上述代码设计并无不同,这里不再赘述。服务之间交叉请求,形成一个如图所示网格状,这也是服务网格的由来。
(图片来自网络)
边车的名字主要因为服务治理进程和服务部署在同一主机环境中,就像下图的车。

(图片来自网络)
这种模式优点在于将服务治理与业务代码分离开,且不会有集中式网关的单点问题,还可通过控制面进行统一管理,方便和 K8s 整合,是云原生架构的重要突破。在服务调用时因为多了两跳,有一定的性能影响。
本章内容实现了熔断设计,文章相关代码请参阅 https://github.com/skyhackvip/service_breaker
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。







